
Takeaways from the “Defining Open AI” community workshop
The Open Source Initiative is deep into a multi-stakeholder process to define machine learning systems that can be characterized as “Open Source.”
About 40 people put their heads together for the first community discussion in an hour-long session I led at FOSSY 2023.
If you missed it, there are still plenty of ways to get involved. Send a proposal to speak at the online webinar series before August 4, 2023 and check out the timeline for upcoming in-person workshops. Get caught up with the recap from the kickoff meeting, too.
Why data is the sticking point of machine learning
The session started with a short presentation highlighting why we need to define “open” in the AI context and why we need to do it now.

Open Source gives users and developers the ability to decide for themselves how and where to use the technology without the need to engage with a third party. We want to get the same things for machine learning systems. We’ll need to find our way there.
First, we need to clarify that machine learning systems are a little different than classic software. For one, machine learning depends on data, lots of it. Developers can’t rely on just their own laptops and knowledge to build new AI systems. The legal landscape is also a lot more complicated than for pure software: Data is covered by a lot of different laws, often very different between countries.
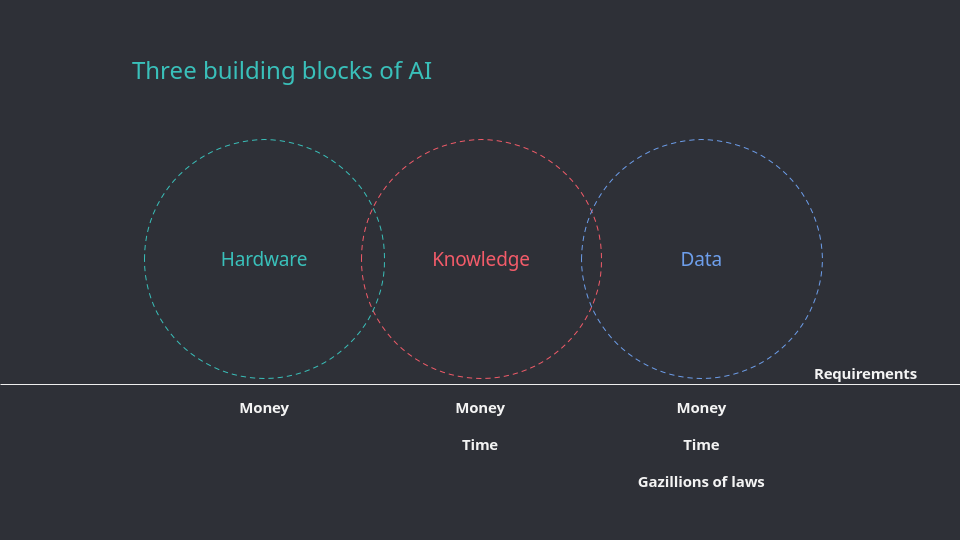
After the initial meeting in San Francisco, it became clear that the most crucial question to ask (and try to answer) is around data.
At the Portland session, I asked one simple question:
How tightly coupled should the original data and the ML models be?
I started with the three pieces that go into a typical ML system:
- Software for training and testing, inference and analysis
For the crowd it was easy to agree that all software written by a human and copyrightable must be Open Source for a ML system to be considered open. - Model architecture with its weights and training parameters
These should be made available with terms and conditions that don’t restrict who can use them and how they’re used; There also shouldn’t be restrictions on retraining the artifacts and redistributing them. The group wasn’t as clearly in agreement on this point but did concur that resolving this is within reach. - Raw data and prepared datasets, for training and testing
I started with the assumption that the original dataset is not the preferred form for making modifications to model/weights and asked the group: Does that mean an “Open ML” can ignore the original data? How much of the original dataset do we need in order to exercise the right to modify a model?
This final question required people to get on the same page. Some AI developers in the room shared their views that the original dataset is not necessary to modify a model. They also stated that they would need a sufficiently precise description of the original data, though, and other elements. This would be necessary for technical reasons and for transparency, to evaluate bias, etc.
A few people took a different view, leaning more on the fact that data is somewhat equivalent to the source code of a model and the model is the binary, as if training was the equivalent of compilation. Some of their comments gave the impression that they were less familiar with developing ML systems.
Other participants explained why the analogy to software’s source-binary doesn’t hold water: A binary-only piece of software cannot be modified and in fact the GNU GPLv3 explains in detail the preferred methods of making modifications to software. On the contrary, AI models can be modified to be fine-tuned and retrained without the original dataset, if they’re accompanied by other elements.
During the session, folks were encouraged to contribute their thoughts on an Etherpad. Comments there touch on the cultural implications of public data, the importance of documenting data transparency and whether “open with restrictions” carve outs will be necessary when it comes to personal or health data.
What’s next
Remember: We want you to weigh in with a proposal to speak and invite you to participate in upcoming community workshops.
For now, we’ll leave you with this quote from the Portland session:
“I think I’m coming to a position that AI maybe isn’t open without open data or a really good description of the data used (based on the “spigot” example), but that there will be a significant number of use cases that aren’t open, for various cultural reasons e.g. they may use other licenses, defined within those communities, but also aren’t the kind of extractive commercial stuff that invokes puking either. Open isn’t an exclusive synonym for ‘good’.”
Participants also debated on the legality of training models on copyrighted and trademarked data, and voiced concerns about the output of generative AI systems.
We have a long road ahead and must move quickly – join us on this important journey.
Reposts
Likes